
ChooseBrew
Overview
Picture this: It’s Friday night. You promised that you would hang out with some of old college buddies who you haven’t seen for years (and frankly, you had wanted to keep that way), and they suggest a beer night. So, you leave your apartment anticipating the nightmares of Keystone Light.
But wait? What’s that? You’re going to Other Half out in Brooklyn? Seems like your friends are now beer snobs, and you have some catching up to do. But when every beer has notes of this, a hint of that, how can you even begin to navigate the world of beer?
ChooseBrew is an application that I built that uses natural language processing to extract a beer’s intrinsic flavor profile, and then leverages user ratings to create a collaborative filter recommender similar beers.
Obtaining and Cleaning the data
In order to get started, I needed to find reviews to create my corpus. Using BeerAdvocate.com as my site to scrape, I used BeautifulSoup to scrape metadata and ratings from over 9,000 beers.
After a bit of filtering, I was able to get 9,156 beers with 130 ratings or more. This came out to 1.2 million ratings total, but only 25% of the ratings had actual reviews. At the end of the day, my corpus had 311K documents, where each document was a review for a given beer.
TF-IDF
After lemmatizing my corpus and removing for stopwords, it was time to attempt topic modeling. I turned to TFIDF and Non-negative Matrix Factorization to accomplish this. CountVectorizer and Latent Dirichlet Allocation were also used, but did not achieve topics as succinct as the former combination.
Trying to find succinct topics was a very manual process, so heres the workflow in a nutshell:
- Run TFIDF and NMF and print topic words derived from NMF
- If topics words don’t make sense, tweak min_df and max_df parameters within TFIDF to pare down fluffy words and unique-but-not-useful words in corpus
- Once topics make sense with the given min_df and max_df, play around with the number of topics (n_components) in NMF to find succinct topics.
I ended up with these topics after many iterations:

Lets assign a label to a topic for human readability:
Topic #0: Yeasty
Topic #1: Citrus
Topic #2: Balance
Topic #3: Chocolatey
Topic #4: Earthy
Topic #5: Tropical
Topic #6: Piney
Topic #7: Spiced
Topic #8: Roasted
Topic #9: Sour
Assigning a Flavor Profile to a Beer
Through NMF, I had flavor “weights” for each review, but didn’t have the flavor “weights” for the actual beer. To do so, I grouped the reviews by beer and the took the average of all the reviews to get my weights by beer. I then reexpressed each beer’s weights as a probability distribution where the sum of all flavor “probabilities” was equal to 1. Next, I took the index of the highest flavor probability per beer and assigned the corresponding flavor profile to the given beer.
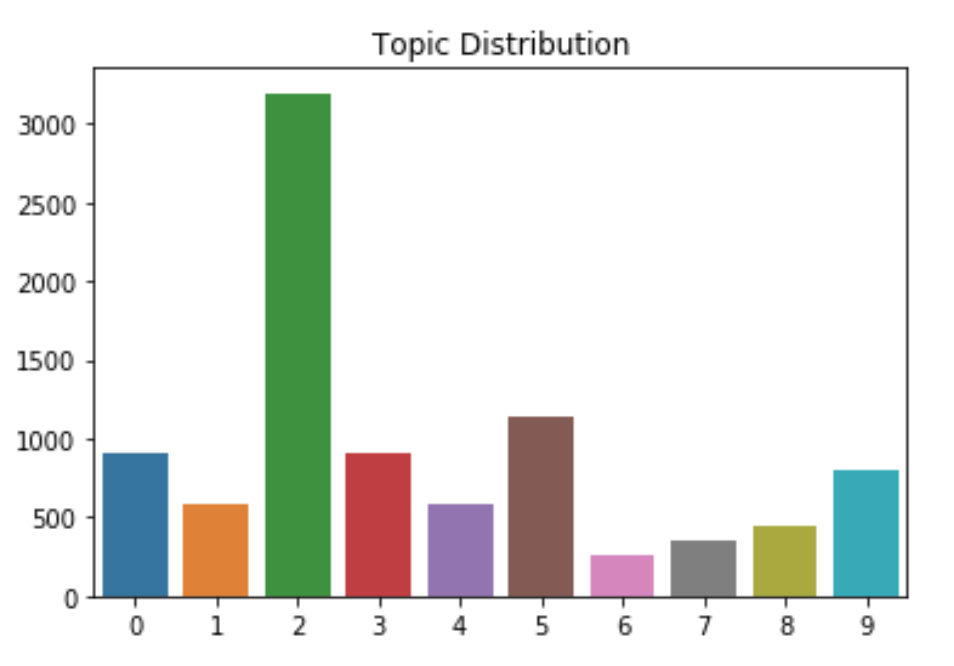
My beer distribution by flavor profile ended up assigning a significant portion to Topic 2, or Balance. While this may be true for a lot of beers, I wanted my recommender to be able to recommend beers that have specific profiles. I went back to the review weights and added a penalty weight to the Balance Topic such that only beers that heavily index towards Balanced will be in the Balanced Flavor Profile. Below is the chart after the penalty weight:
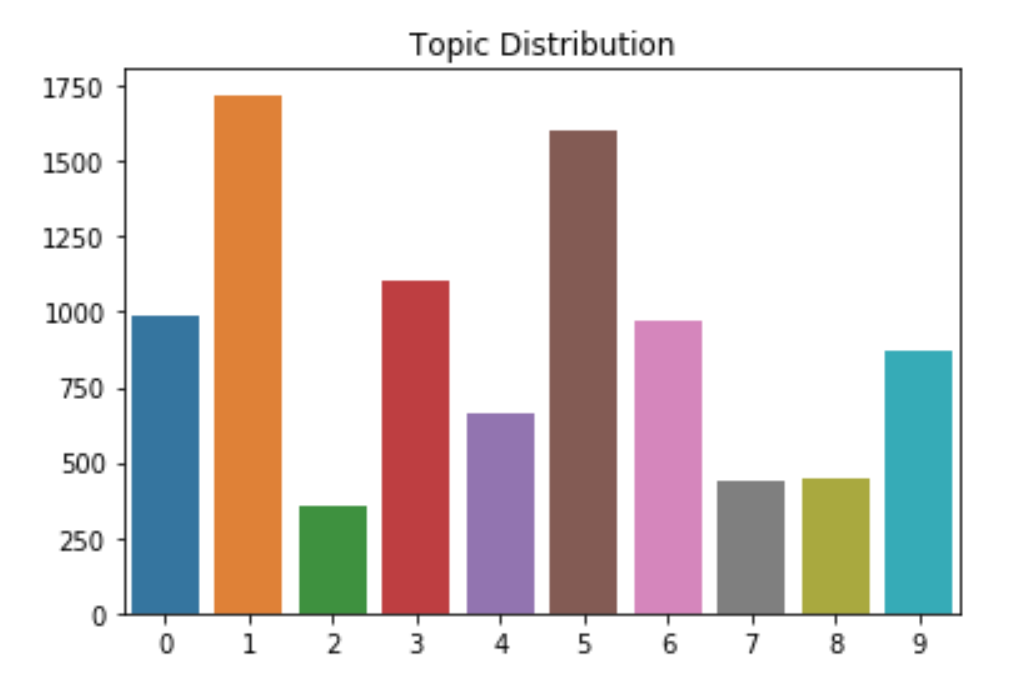
I’m a little happier with this outcome. Although some flavors dominate the dataset (curse you IPAs!), a given flavor profile still has less than 20% of all the beers.
Heres a nice t-SNE visualization of all the beers:
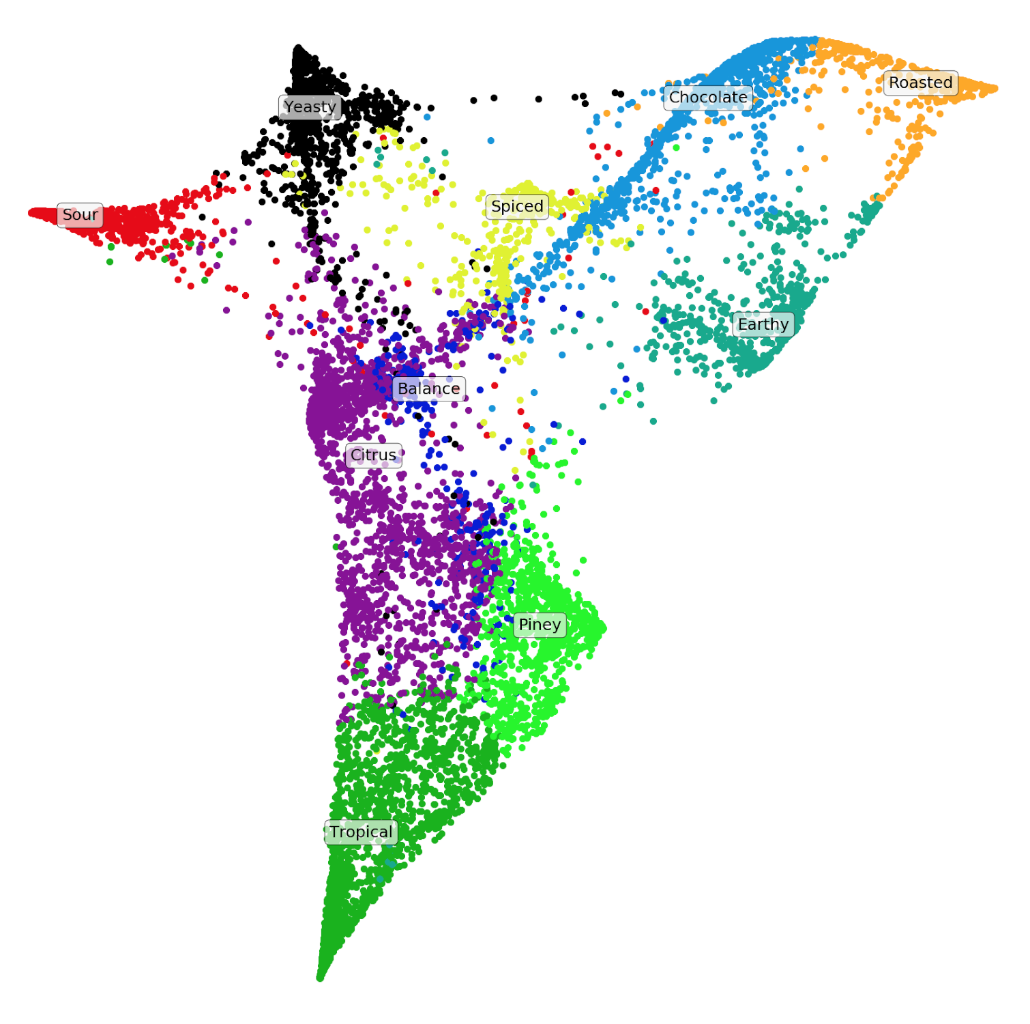
For a t-SNE visualization, interpretation relies on where a topic’s position is relative to another. This can be interpreted as:
- Roasted, Sour, and Tropical are the least similar
- Roasted, Chocolate, and Earthy are fairly similar
- Piney, Citrus, and Tropical are fairly similar (probably because of all those IPAs!)
- Citrus is fairly similar to both Tropical and Sour
Building the Recommender
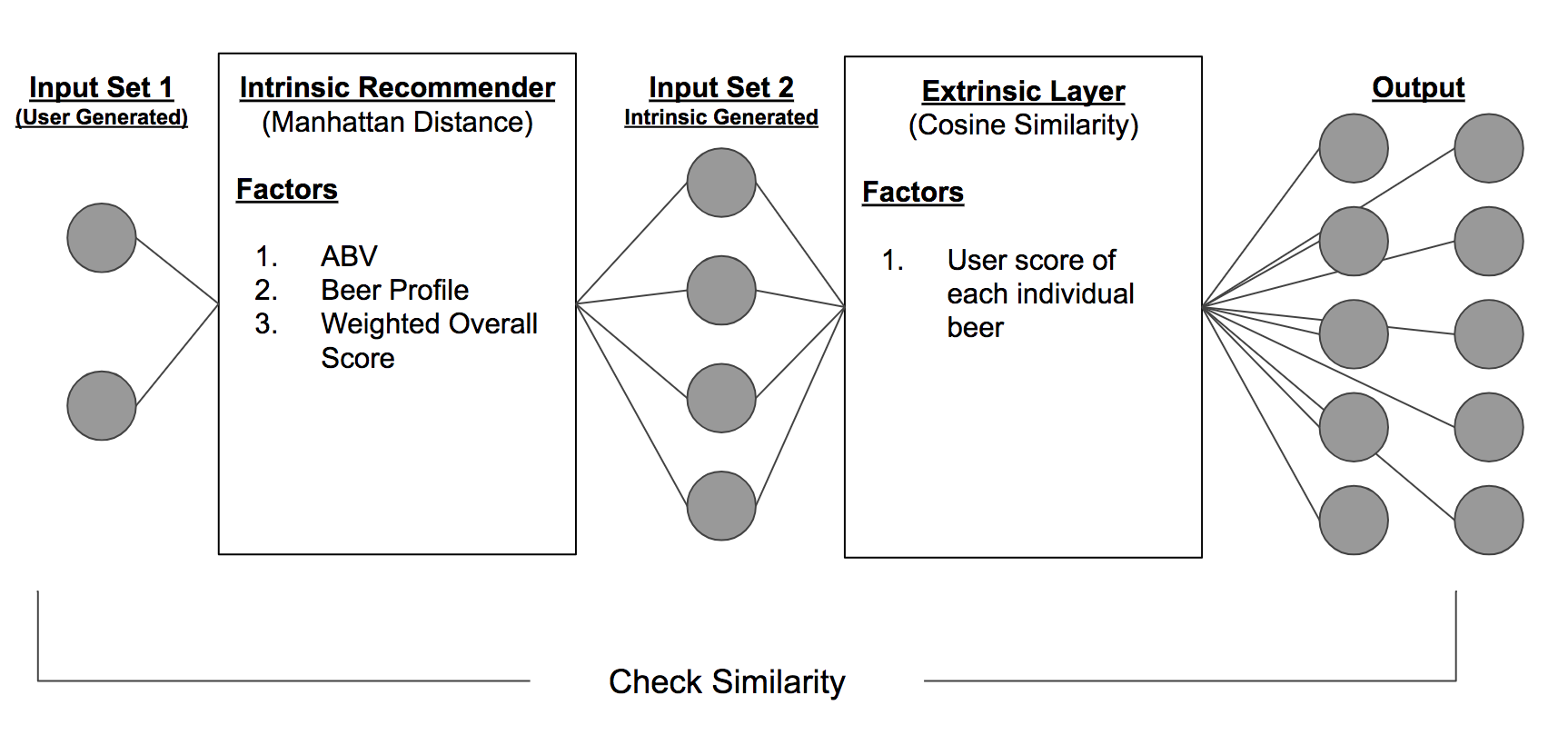
I first created an content-based recommendation engine using ABV, weighted average score, and the flavor profile distributions from the NMF. A content-based recommender is a recommender that leverages the intrinsic characteristics of an object to find other objects similar to it.
In this case, ABV and flavor are both inherent to a beer. You could argue that weighted average score takes into account a beer’s popularity and demand by combining the volume of reviews with the how high the ratings.
After using Manhattan Distances to calculate distances between all beers, I could query for a beer, and get the beers closest to it. However, since these results are based on beers that are similar by taste, results may not be too exciting or trustworthy.
That’s where the the collaborative filter comes in. By taking a matrix of beers by user ratings and finding the cosine similarity between all the beers, I am able to find similar beers that users have enjoyed. And by layering the recommendations from the content-based filter and feeding them into the collaborative filter, I am able to alleviate the cold start problem.
But how do my recommendations from my convoluted content-to-collaborative recommender compare to the original input? By taking the Manhattan Similarity Score (1 / 1 + Manhattan Distance) of the outputs back to the original input, I am able to see how out of the ordinary my recommendations are.
You can check out my application in action through the video above. I have plans to try to host this application in the future once I figure out how to host and call my files through S3.
Thanks for reading!